
В эпоху стремительного развития искусственного интеллекта и появления все более сложных языковых моделей, таких как LLaMA, GPT и Gemini, понимание их базовых механизмов становится ключом к эффективному использованию. Одним из таких фундаментальных понятий является контекстное окно. Это не просто технический термин, а краеугольный камень, определяющий, насколько «умной» и «понимающей» может быть нейросеть в работе с информацией.
Если вы хотите углубиться в статистику и метрики, связанные с поведением и возможностями нейросетей, посетите www.ai-stat.ru для получения более детальной информации. Но давайте сначала разберемся, что же такое контекстное окно и почему оно так важно для работы LLaMA и других передовых LLM.
Понимание этого аспекта поможет вам не только более эффективно формулировать запросы, но и выбирать подходящую модель для конкретных задач, максимально используя ее потенциал.
Что такое контекстное окно?
Представьте, что вы разговариваете с очень внимательным собеседником. Он помнит все, что вы сказали с самого начала разговора, и использует эту информацию для формирования своих ответов. Контекстное окно в большой языковой модели (LLM) — это аналогичная «кратковременная память» нейросети. Это максимальное количество токенов (слов, частей слов, знаков препинания), которое модель может одновременно удерживать в уме и анализировать для генерации следующего фрагмента текста.
Этот «объем памяти» включает в себя как ваш запрос (промпт), так и весь диалог, предшествующий текущему ответу модели. Чем больше контекстное окно, тем обширнее объем информации, который модель способна осмыслить и учесть при выполнении задачи, что напрямую влияет на качество и релевантность ее ответов.
Зачем контекстное окно так важно для LLM, включая LLaMA?
Размер контекстного окна напрямую определяет сложность задач, с которыми может справляться языковая модель, и глубину ее понимания. Влияние огромно: от способности поддерживать связный и продолжительный диалог до анализа объемных документов.
Значение контекстного окна можно проиллюстрировать следующими аспектами:
- Связность диалога: Модель с большим контекстным окном лучше «помнит» предыдущие реплики и может поддерживать логичную беседу на протяжении долгого времени, избегая повторений и потери смысла.
- Анализ больших текстов: При работе с документами, книгами или кодом, большое контекстное окно позволяет модели охватить весь материал, не теряя важные детали и взаимосвязи.
- Сложные задачи: Для резюмирования длинных статей, написания развернутых отчетов или создания сложных программных функций необходимо, чтобы модель могла одновременно обрабатывать множество зависимостей и фрагментов информации.
Без достаточного контекста даже самая мощная нейросеть будет выдавать поверхностные или несвязанные ответы, поскольку ей будет не хватать «памяти» для глубокого анализа.
Как работает контекстное окно: от ввода до вывода
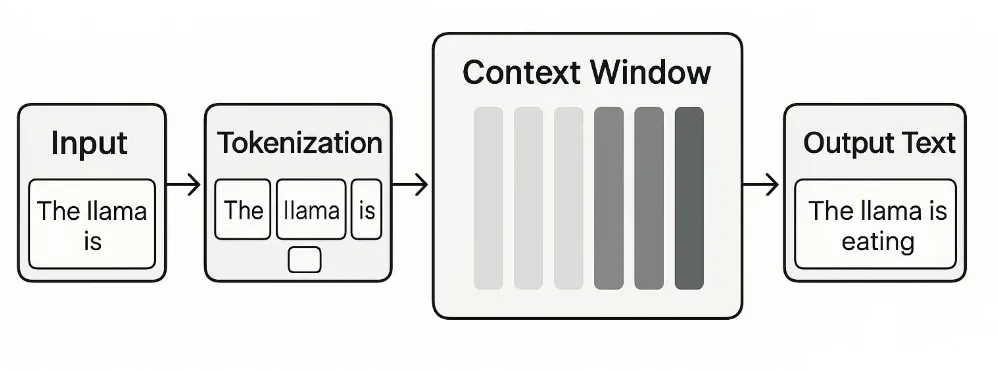
Каждый раз, когда вы взаимодействуете с языковой моделью, ваш запрос (промпт) преобразуется в токены. Модель анализирует эти токены вместе с предыдущими токенами диалога (если они помещаются в контекстное окно) и на основе этого генерирует ответ.
Давайте рассмотрим ключевые этапы:
- Токенизация: Весь текст (ваш промпт и предыдущие реплики) разбивается на мелкие единицы — токены. Один токен может быть словом, частью слова, символом или знаком препинания.
- Обработка: Эти токены передаются в нейронную сеть, которая анализирует их взаимосвязи, порядок и значение в рамках заданного контекстного окна.
- Генерация: На основе этого анализа модель предсказывает наиболее вероятный следующий токен, затем следующий, и так далее, пока не будет сформирован полный ответ.
Если объем входных данных превышает размер контекстного окна, модель «обрезает» старые токены, чтобы освободить место для новых. Это означает, что информация, находящаяся за пределами окна, «забывается», что может привести к потере контекста и менее точным ответам.
Контекстное окно в моделях LLaMA
Модели семейства LLaMA от Meta, разрабатываемые с фокусом на открытость и доступность, демонстрируют значительный прогресс в работе с контекстом. Ранние версии имели относительно небольшие контекстные окна, но с каждой новой итерацией этот параметр увеличивается, расширяя возможности моделей. Например, в LLaMA 3 и особенно LLaMA 4, контекстное окно значительно выросло, что позволяет им обрабатывать более сложные и объемные задачи.
Постоянное совершенствование архитектуры LLaMA, включая такие инновации как MoE (Mixture-of-Experts), напрямую влияет на эффективность использования и расширение контекстного окна. Эти изменения делают модели LLaMA все более конкурентоспособными в сценариях, требующих глубокого понимания больших объемов данных. Подробнее об архитектурных особенностях и новых возможностях последних версий вы можете узнать из обзора, посвященного развитию моделей LLaMA.
Контекстное окно в других LLM: Сравнение и перспективы
Размер контекстного окна — один из ключевых показателей при сравнении различных LLM. На рынке представлены модели с очень разными возможностями.
| Модель/Семейство моделей | Ориентировочный размер контекстного окна (токены) | Примечания |
|---|---|---|
| LLaMA 2 | 4 096 – 8 192 | Ранние версии, ограниченные для объемных задач. |
| LLaMA 3 | 8 192 – 128 000+ | Значительное увеличение, поддержка более сложных задач. |
| LLaMA 4 | 128 000 – 1 000 000+ | Последние версии с максимальным контекстом для масштабного анализа. |
| GPT-3.5 | 4 096 – 16 384 | Стандартные и расширенные версии для разных нужд. |
| GPT-4 | 8 192 – 128 000 | Значительно улучшенное понимание и генерация в больших контекстах. |
| Gemini 1.5 Pro | 128 000 – 1 000 000 | Одно из самых больших контекстных окон, нативная мультимодальность. |
Примечание: Размеры контекстных окон могут варьироваться в зависимости от конкретной версии модели, настроек и производителя. Указаны ориентировочные значения.
Как видно из таблицы, тренд очевиден: разработчики стремятся к увеличению контекстного окна, чтобы модели могли работать с еще большими объемами информации, приближаясь к человеческому пониманию целостных текстов и диалогов.
Практическое применение и ограничения большого контекстного окна
Большое контекстное окно открывает новые горизонты для применения LLM в самых разных сферах. Это позволяет нейросетям не просто генерировать текст, а выступать в роли мощных аналитических инструментов.
Вот некоторые из наиболее значимых применений:
- Резюмирование и извлечение информации: Модель может прочитать длинный научный труд, книгу или отчет и выделить ключевые идеи, создать аннотацию или ответить на конкретные вопросы по всему документу.
- Написание и анализ кода: Программисты могут подавать большие блоки кода или целые файлы для отладки, рефакторинга или генерации новых функций, полагаясь на то, что модель «видит» всю логику.
- Креативное письмо: Сценаристы или авторы могут создавать целые истории, поддерживая сквозной сюжет и последовательность персонажей на протяжении многих страниц.
- Помощники для юристов и исследователей: Анализ объемных юридических документов, научных статей, поиск прецедентов становится намного эффективнее.
Однако, даже с огромным контекстным окном существуют свои нюансы. Иногда модели могут «терять» важную информацию, расположенную в середине очень длинного контекста – это явление известно как «lost in the middle». Кроме того, обработка большого контекста требует больше вычислительных ресурсов и времени, что может влиять на скорость ответов и стоимость использования.
Правильное составление запросов (промптов) становится еще более критичным при работе с большими контекстами, чтобы направлять внимание модели на наиболее важные части информации. О том, как максимально эффективно взаимодействовать с LLaMA и получать точные ответы, вы можете прочитать в материале, посвященном составлению запросов.
Будущее контекстного окна
Развитие контекстного окна не стоит на месте. Исследователи постоянно ищут способы преодолеть текущие ограничения, стремясь к созданию моделей с практически «бесконечным» контекстом. Это позволит LLM не просто обрабатывать тысячи или миллионы токенов, а фактически «знать» всю информацию, которую когда-либо им предоставляли, или которую они сами сгенерировали.
Инновации в этой области включают разработку новых архитектур, более эффективных механизмов внимания и использование внешних хранилищ памяти. Такие прорывы обещают радикально изменить то, как мы взаимодействуем с ИИ, открывая путь к более глубокому, надежному и автономному искусственному интеллекту, способному к непрерывному обучению и адаптации. Следить за актуальными исследованиями и тенденциями, а также изучать базовые понятия в области LLM, можно на специализированных ресурсах, где регулярно публикуются обзоры последних достижений и фундаментальные принципы работы.
Заключение
Контекстное окно — это не просто техническая характеристика, а фундаментальный аспект, определяющий интеллектуальные возможности и практическую ценность больших языковых моделей, таких как LLaMA. Чем больше контекстное окно, тем глубже понимание, выше связность и шире спектр задач, которые может решать нейросеть.
По мере того, как LLaMA и другие LLM продолжают развиваться, мы видим постоянное расширение их «памяти», что открывает двери для все более сложных и инновационных приложений. От анализа огромных данных до создания целостных произведений искусства — понимание и оптимизация контекстного окна остается одним из ключевых направлений в стремлении к созданию по-настоящему интеллектуальных систем.



